在人家网站上看到好的东西就想据为己有,这是人之常情。比如图片,音乐,视频,文字。一般来说,我们美其名日“分享”、“转载”。可是作为程序员来说,已经不满足于这种小部分的攫取了,我们野心勃勃想要把人家的网站变成自己的,就好比是把人家的设计方案拿过来当成是自己的。当然,涉及道德和法律层面的东西,自行恶补。关于“技术是把双刃剑“,“能力越大,责任越大”的话题讨论很多,不作为今天的目的。我要说的只是技术层面的仿站的重要的一部分——扒网站。
所谓扒网站,就是把目标网站的静态部分存储到本地,包括其中的js,css,image文件,最终实现在本地打开如同访问目标网站一样的视觉效果。请注意,仅仅是视觉效果。数据和逻辑的部分我们是不可能直接拿到的,除非利用其它方法,希望你懂得。当得到了这些后就相当于完成了建站的重要一环——前端部分。
好了,下面进入正题。
先举个小例子吧,
拿某头条网站的一个页面开刀。
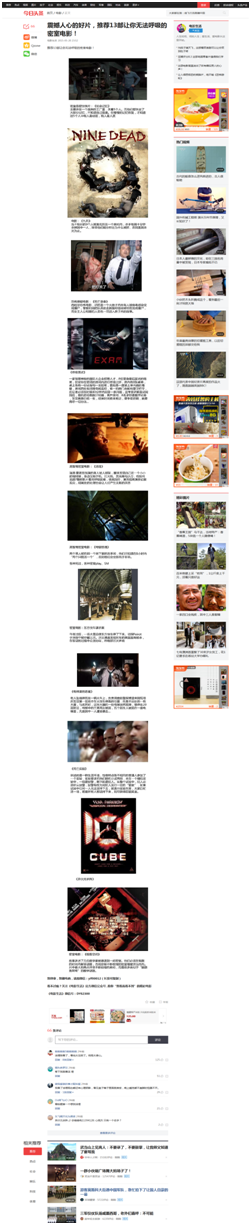
如上图是地址
http://www.toutiao.com/a4386544608/的全部页面,我们先用最简单暴力的方式来获取它。
不管你用的是什么浏览器,找到文件菜单,页面另存为,保存类型选择全部,然后在你选择的路径就能找到页面文件了。一共有两个文件,一个为html文件,另一个是文件夹,包含所有的css,js,图片以及一些垃圾文件。打开其中的html文件,就可以看到想到的效果了。

关于打开后的效果我就不在这里放图了,直接说说这种做法的缺点吧:首先是不能保证效果,仍然会有部分图片或功能不正常,其二是文件混乱,图片,css,js文件不是按照分类存放的,不方便使用。其三是有太多的冗余文件了,需要花时间去判断价值。当然这种方法也有好处,就是简单粗暴。不过我还是喜欢做个优雅的男士,建议采用更优雅的方式,比如下面我要讲的。
第一步,准备工作。先建好一个准备存放文件的目录,并在其中分别新建css,js,image三个目录以备使用。
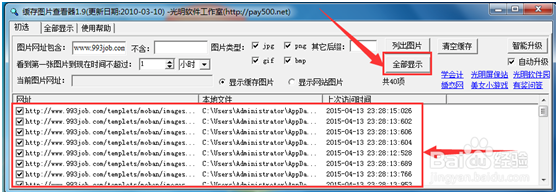
第二步,下载图片。如果使用火狐浏览器,在菜单栏找到工具,依次打开工具,页面信息,选择媒体项,crtl+A全选后,点击右下角的另存为,保存到预先建好的images文件夹。如果使用其它浏览器,可以借助另一款小工具,缓存图片查看,使用简单就不介绍了。
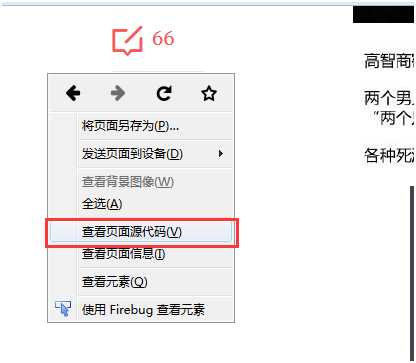
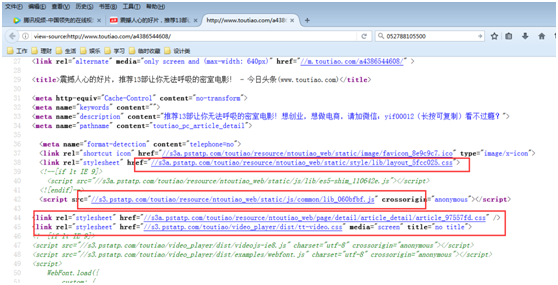
第三步,下载css,js文件。如果是火狐浏览器,在页面空白处右键选择查看页面源代码;如果是IE浏览器右键选择查看源,或者菜单选择查看——源;至于其它浏览器自己找规律吧,都是大同小异的。这样就可以看到页面的html源码了,接下来用ctrl+f,分别搜索css,js,找到引用的位置,在新窗口打开。然后在空白处右键另存为,存放目录选择预先建好的css或js目录,名称最好就用以前的名字。有个不好的消息是,每个网站对文件路径的写法都不太相同,就要区别对待。比如说咱们举例的这个页面是这样写的,”
//s3a.pstatp.com/toutiao/resource/ntoutiao_web/static/style/lib/layout_5fcc025.css”,虽然以双斜线开始,其实是引用的其它网站的文件,可以直接打开;但是有的网站是按网站绝对路径来写的,有的是按当前页面相对路径来写,还有的会以逗号隔开代表同一目录下的两个文件,所以需要根据不同情况自行拼接。注意不要有遗漏,否则显示或功能上就不正常了。
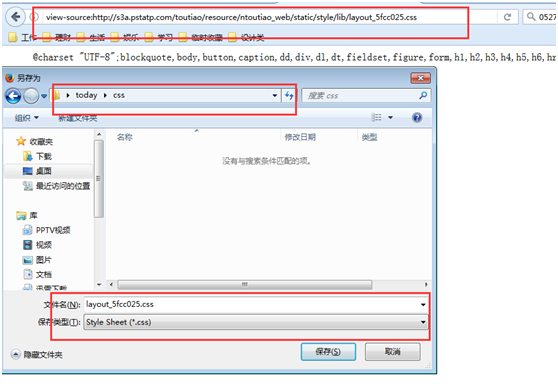
第四步,下载页面的html源码。很简单,直接把上一步打开的html源码右键另存为到指定目录就可以了。保存类型请选择仅html,并且建议名称为index.html或default.html。
第五步,修改路径。这是最后一步也是最关键最复杂的一步了。使用文本编辑器打开上一步存储的html页面,依次找到css,js,image的引用路径,全部修改为当前页面的相对路径。同样的,在css文件中也会有以background属性使用图片的,也需要更改。不过考虑到文件较多,我的做法是先运行看到异常后再找到相应文件修改。
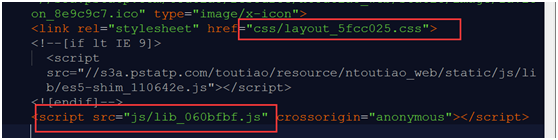

如此一番周折后便是大功告成了。虽然过程复杂,但是对于后期使用是相当方便的。我也想过写一个小程序执行自动解析下载,可是试了很多次总是会有考虑不到的地方,尤其是解析文件路径的地方,只能怪我前端水平和正则水平不够高了。所以我在网络上寻到一款扒网站的小工具,很容易就能实现以上的效果,稍后会在下面放上链接。不过,还是建议把这些方法get到,总是会用得到的。
仿站工具链接:
http://pan.baidu.com/s/1hsstpSK 密码: b31m
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏