本文字数:5939字
预计阅读时间:15 分钟

概述
长按图片识别二维码在移动端是很常见的操作,长按后需要对图片进行识别,并且将二维码中所包含的数据解码出来。在我们的业务场景中,是通过点击图片进入大图预览页面。长按大图预览的图片,会识别图片中的二维码,并且显示有跳转按钮,提示用户可以跳转二维码对应的页面。
但是,在现有业务场景中,要求图片中二维码不能在视觉上占据太大的位置,所以只能以很小的尺寸显示在下面。为了更好的配合公司现有业务,保证对图片中二维码的识别率,所以需要对二维码识别进行优化。
优化方案
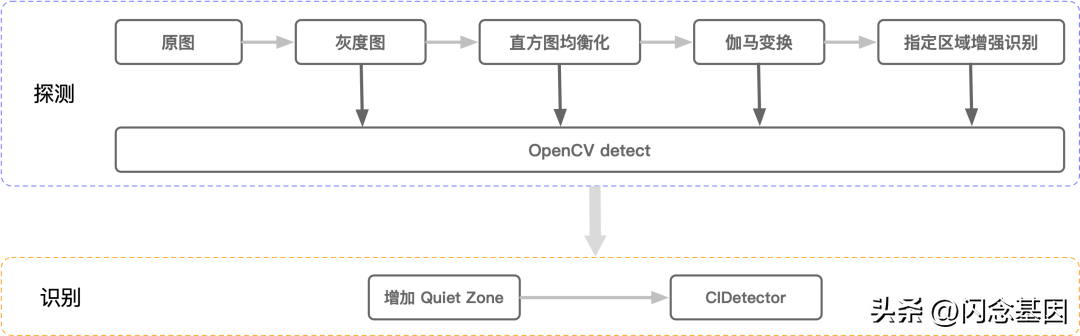
方案总体分为探测和识别两个核心流程,探测流程主要由图像处理算法,以及OpenCV来实现,识别流程主要由系统AVFoundation库的CIDetector来实现。先将二维码所在区域探测出来,随后对这个区域进行识别增强的处理,以实现模糊、较小的二维码的识别。
探测流程
因为不是每一张图片上都有二维码,探测的意义在于,查找图片中是否有二维码,以及二维码在图片中的位置。从而进行后续的针对性处理。以下,任何一步探测有结果,都将进入识别流程中,并且将探测到的位置传给识别方法。
- 第一次探测。转灰度图,通过OpenCV的cvtColor函数,将四通道的RGBA图片,转换为单通道的灰度图。
- 第二次探测。通过算法进行直方图均衡化(非自适应,并且限制对比度),目的是让图片内轮廓清晰。
- 第三次探测。通过算法进行伽马变换,目的是增强图像对比度。
- 第四次探测。将原始灰度图的下面20%的右半部分,clone到一个新的Mat对象中,并且进行3.5倍的resize。将得到后的灰度大图调用detect进行探测。
- 第五次探测。将原始灰度图的下面20%的左半部分,clone到一个新的Mat对象中,并且进行3.5倍的resize。将得到后的灰度大图调用detect进行探测。
- 探测结束。在二维码的定位图形、码元等核心信息没有受损的前提下,这时候基本断定这张图片上没有二维码。
需要注意的是,在探测方案中,为什么选取下面左右两边的20%着重进行探测。是因为根据对公司实际业务的调研,绝大多数的二维码都是在图片的右下角位置,其次是左下角。以公司业务为例,目前没见过将二维码放在图片中间的场景。
识别流程
- 探测到二维码后,会将当时用来探测的图片,以及探测到的二维码区域传递给识别方法。传递过来的图片,可能是resize后的大图,对这些大图识别率会更高。
- 从传递过来的图片上,根据二维码所在区域的坐标系,将二维码所在的部分,重绘到一个新的位图对象上。为了保证识别效果,会在重绘时加上一个15的外边距,以保证二维码Quiet Zone的特性。
- 用重绘后的二维码,调用AVFoundation的CIDetector进行识别,并获取识别后的字符串。
为什么不把探测和识别都交给OpenCV来做。这是因为经过我的测试,我发现OpenCV的识别率较低,远不如CIDetector的识别率。所以,只将探测部分交给OpenCV,但不让OpenCV去识别二维码。
根据OpenCV的detect函数的源码进行查看,发现OpenCV的探测是基于定位符号进行探测的,分为横向和纵向两个方向进行探测,使用OpenCV进行探测是不错的选择。但是OpenCV识别率并不高,所以用OpenCV进行探测,结合AVFoundation进行识别的方案,是一个比较不错的策略。
代码实现
方案总体代码量较大,这里列出了一些主要方法的代码实现。探测方法内部实现,会进行不同程度的增强扫描和识别。方案中使用了一些OpenCV的API,可以通过OpenCV官方文档了解下API的定义和调用。
生成灰度图
把传入的图片转为OpenCV可以识别的Mat的灰度图,灰度图色彩通道只有一个,在进行后续计算上,会节省很多性能。随后进入后续的探测部分,探测到二维码后,会将二维码拼接业务参数,并在主线程中返回给调用方。
方法的核心逻辑有两部分,一是将UIImage转为OpenCV类型的Mat对象,二是将四个颜色通道的彩色图,转为单个颜色通道的灰度图。二值图和灰色图是不同的,灰色图是单个通道,每个单位占8位,表示范围是0~255。二值图只有0~1的展示,所以识别速度会相对快一些。
这里简要讲一下颜色通道的概念,CV_8UC4表示RGBA四颜色通道,占用32位空间。同样的,也有三颜色通道RGB,以及两个通道和单通道,两个通道的CV_8UC2我没用过,不知道什么场景下会需要。cvtColor函数是OpenCV中进行颜色空间转换的函数,可以将彩色图修改为灰度图。
CGFloatrows = sourceImage.size.height; CGFloatcols = sourceImage.size.width; cv::Mat cvMat(rows, cols, CV_8UC4); CGColorSpaceRefcolorSpace = CGImageGetColorSpace(sourceImage.CGImage); CGContextRefcontext = CGBitmapContextCreate(cvMat.data, cols, rows, 8, cvMat.step[0], colorSpace, kCGImageAlphaNoneSkipLast | kCGBitmapByteOrderDefault); if(context == NULL) { returncvMat; } CGContextDrawImage(context, CGRectMake(0, 0, cols, rows), sourceImage.CGImage); CGContextRelease(context); CGColorSpaceRelease(colorSpace); cv::Mat grayMat; cv::cvtColor(cvMat, grayMat, cv::COLOR_BGR2GRAY); returngrayMat;
resize
下面代码是对左下和右下两个部分进行探测的逻辑,代码中scale代表局部放大的倍数。根据公司业务,先从右下角进行放大及探测。放大需要获取到像素的行数和列数,这些Mat提供了对应的API。
下面是核心逻辑的梳理。
- 通过rowRange和colRange获取到需要增强扫描的像素,例如右下角区域的横排和竖排的像素。
- 调用clone将像素取出,并赋值给Mat。
- 调用resize函数扩大到对应的倍数。
需要注意的是,在下面方法的第二段,对右下角进行了强制识别。是一个容错处理,属于“闭眼识别”。第一步无论是否有探测的结果,都会对右下角进行二维码的识别。因为在测试中,对于非常小的二维码,会出现对于resize后的灰度图,探测不到但是能识别到的情况。所以,增加了右下角没有探测到,但依然进行强制识别的逻辑。
CGFloat scale = 3.5f; cv::Mat copyMat = grayMat.rowRange(grayMat.rows * 0.8, grayMat.rows).colRange(grayMat.cols * 0.5, grayMat.cols).clone(); cv::Mat resizeMat; cv::resize(copyMat, resizeMat, cv::Size(grayMat.cols * scale * 0.5, grayMat.rows * 0.2* scale)); NSString *result = [selfqrcodeQRCodeForGrayMat:resizeMat]; /// 闭眼识别if(!result.length) { UIImage *image = [selfUIImageFromCVMat:resizeMat]; result = [selfreadQRCodeWithImage:image detectorAccuracy:CIDetectorAccuracyHigh]; } if(!result.length) { copyMat = grayMat.rowRange(grayMat.rows * 0.8, grayMat.rows).colRange(grayMat.cols * 0.f, grayMat.cols * 0.5).clone(); cv::resize(copyMat, resizeMat, cv::Size(grayMat.cols * scale * 0.5, grayMat.rows * 0.2* scale)); result = [selfqrcodeQRCodeForGrayMat:resizeMat]; } returnresult;
识别
识别方法会接收传入的二维码坐标系,裁剪出二维码的位置并做相应的处理,随后交给AVFoundation去识别。当探测不到时,不会进入识别的环节。
当探测到二维码时,可以通过output获取二维码的四个点,顺序是左上、右上、右下、左下,顺时针存储。在原有的四个点外面,加上15个单位的Quiet Zone,随后会将这部分图片裁剪出来,并交给AVFoundation去识别。加入Quiet Zone的原因在于,有Quiet Zone的二维码,识别率会比没有的好。
vector<cv::Point> output; if(output.empty()) { returnnil; } /// 左上cv::Point point0 = output[0]; /// 右下cv::Point point2 = output[2]; CGRectrect = CGRectMake(point0.x, point0.y, point2.x – point0.x, point2.y – point0.y); CGRectinsetRect = CGRectInset(rect, -15, -15); /// rect合法性检查if(insetRect.origin.x > 0&& insetRect.origin.y > 0&& insetRect.size.width > 0&& insetRect.size.height > 0) { rect = insetRect; } UIImage*image = [selfUIImageFromCVMat:grayMat]; image = [selfdrawInRect:rect sourceImage:image]; NSString*result = [selfreadQRCodeWithImage:image detectorAccuracy:CIDetectorAccuracyLow]; returnresult;
Mat转换
在iOS中进行OpenCV开发的过程中,UIImage和Mat的相互转换是经常需要的。UIImage转Mat在生成灰度图的过程中已经涉及,下面的方法是将Mat转为UIImage。核心逻辑就是将Mat的data数据,通过CGImageCreate函数创建CGImage完成的。
CGColorSpaceRefcolorSpace; CGBitmapInfobitmapInfo; size_t elemsize = cvMat.elemSize(); if(elemsize == 1) { colorSpace = CGColorSpaceCreateDeviceGray(); bitmapInfo = kCGImageAlphaNone | kCGBitmapByteOrderDefault; } else{ colorSpace = CGColorSpaceCreateDeviceRGB(); bitmapInfo = kCGBitmapByteOrder32Host; bitmapInfo |= (elemsize == 4) ? kCGImageAlphaPremultipliedFirst : kCGImageAlphaNone; } NSData*data = [NSDatadataWithBytes:cvMat.data length:elemsize * cvMat.total()]; CGDataProviderRefprovider = CGDataProviderCreateWithCFData((__bridge CFDataRef)data); /// 根据Mat创建CGImageCGImageRefimageRef = CGImageCreate(cvMat.cols, // widthcvMat.rows, // height8, // bits per component8* cvMat.elemSize(), // bits per pixelcvMat.step[0], // bytesPerRowcolorSpace, // colorspacebitmapInfo, // bitmap infoprovider, // CGDataProviderRefNULL, // decodefalse, // should interpolatekCGRenderingIntentDefault // intent); UIImage*finalImage = [UIImageimageWithCGImage:imageRef]; CGImageRelease(imageRef); CGDataProviderRelease(provider); CGColorSpaceRelease(colorSpace); returnfinalImage;
收益
统计方案
二维码识别率的统计比较困难,因为场景是在长按图片识别二维码,但图片中是否有二维码,我们并不知道。并且,用户长按操作可能是为了保存图片,并非识别二维码。
所以,数据分析通过A/B测的方式进行,通过分桶方式实现,两个桶分别为50%的用户量。通过这种方式,可以得出一个基本准确的识别数据。
收益数据
数据从两个维度来统计,识别速度和识别率,数据如下。
- 优化方案相对原有方案,识别速度提升6.8%
- 优化方案相对原有方案,识别率提升12%
识别速度OpenCV表现并不是很明显,因为只是通过灰度图的方式提升了识别速度,但如果到了探测的阶段,对速度还是有一定影响的,收益为正数就很不错了。
识别率提升还是不错的,因为是A/B方案的对比,我们并不知道单个方案的真实识别率。但经过我们自测,运营常用的几个存在复杂二维码的账号中,挨个试二维码的识别,自测识别率为100%。
展望
除了灰度图,也考虑过通过OTSU算法将灰度图转为二值图,但是发现二值图在图片清晰度不够的情况下,定位符号比较模糊的位置会被转换为白色。这样,定位符号就会缺一个角,不能构成特定比例,导致识别率出现明显下降。既然二值图的方案都不可行,那就别考虑识别轮廓了,所以就乖乖的用灰度图做识别了。
后续计划加入中值滤波后,再进行OTSU算法做二值化,这样转换后的二值图效果会好很多。
作者:刘壮
来源:微信公众号:搜狐技术产品
出处
:https://mp.weixin.qq.com/s/I9MpbxNvI4fMvbrlX5WhSw
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏