软件开发人员经常遇到“中文乱码”、“软件不能显示日文”等类似问题。真相只有一个——对字符集编码没有一个系统的认知。
常见字符集编码有GB2312、GBK、BIG5、UTF-8、UTF-16,甚至有些从事MFC开发的人可能还会说字符集有ANSI和UNICODE。真的是这样吗?直接上干货。
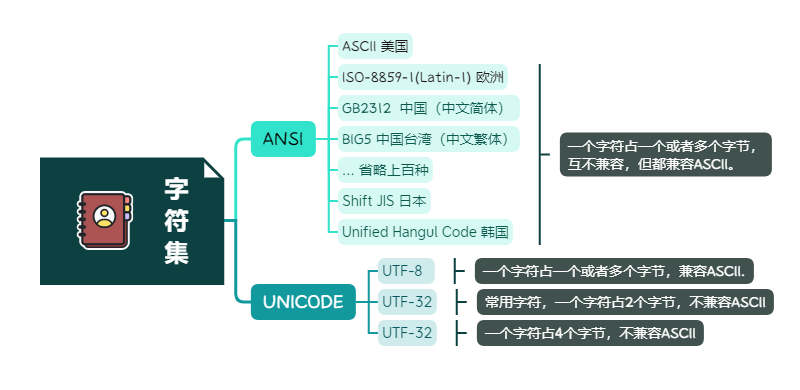
字符集分类
1. ANSI
American National Standards Institute 美国国家标准学会,由这个标准学会制订的一种编码规则。
- 采用多字节系统 (MBCS) 的变长编码,每个字符可以是单个字节、双字节,也可以是多字节的;
- 兼容单字节字符集 (SBCS) 和双字节字符集 (DBCS);
- 兼容 EUC/EUC-CN 双字节编码。由于兼容了这个编码,那么 ANSI 的双字节编码也是大端存储 (Big Endian) 的了;
- 不同的国家和地区可以使用不同的编码规则,这些编码对应到这些国家和地区的代码页 (Code Page) 上。
1.1. ASCII编码
ASCII编码即美国信息交换标准代码(American Standard Code for Information Interchange)是一套共有128个字符的编码,它基于阿拉丁字母,主要作用是用来表示英语和西欧语言字符。ASCII规范编码第一次公布于1967年,ascii码在1986年完成最后一次更新。ASCII码对照表等同于国际标准 ISO/IEC 646,ASCII码对照表是世界最通用的信息交换标准。
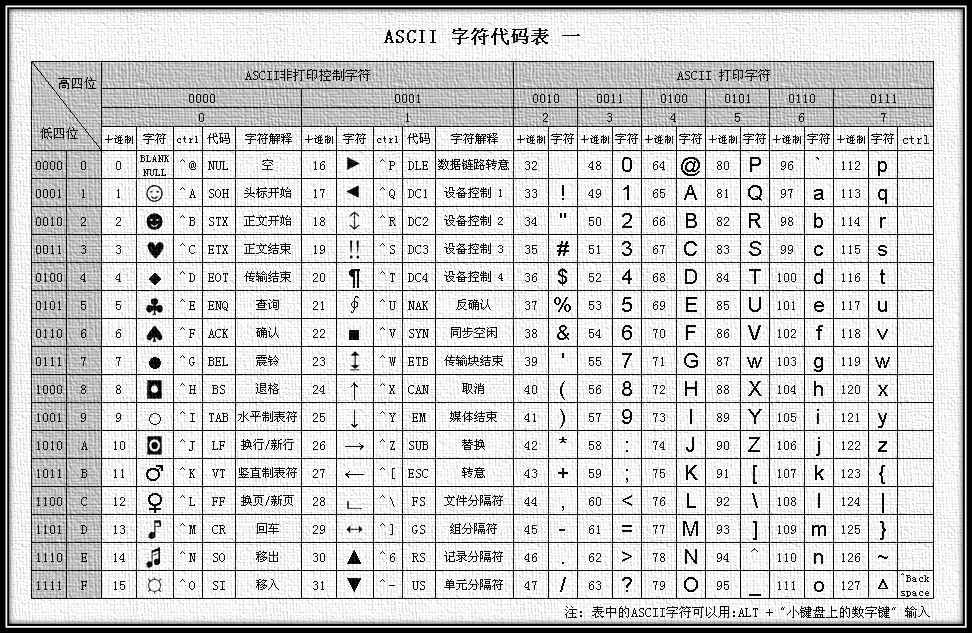
ASCII编码
1.2. GB2312编码
GB2312简体中文编码,一个汉字占用2个字节,在大陆是主要的编码方式,兼容ASCII编码。
为了支持繁体字,于是推出了GBK编码,GBK是国标扩展(Guo Biao Kuozhan)编码的缩写,兼容GB2312。
为了支持少数名民族的文字,于是推出了GB1803,解决了中文、日文、朝鲜语等的编码,兼容GBK。
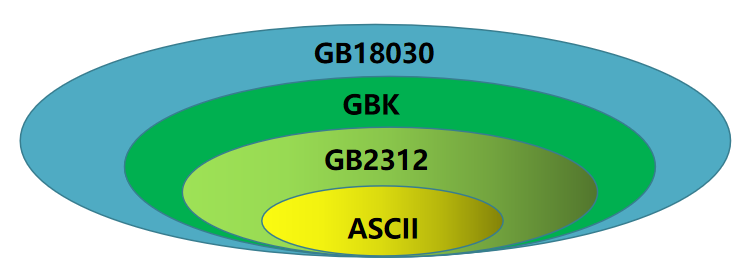
中文编码
2. UNICODE编码
Unicode又称为统一码、万国码、单一码,是国际组织制定的旨在容纳全球所有字符的编码方案,包括字符集、编码方案等,它为每种语言中的每个字符设定了统一且唯一的二进制编码,以满足跨语言、跨平台的要求。
Unicode字符集被划分为 17 个平面(即,17个区,编号为 0-16 ),且具有以下特点:
- 每个平面有216 = 65536个代码点,因此,整个Unicode字符集共有17 × 65536 = 111 4112 个码点。
- 整个Unicode字符集的码点空间为U+000000 ~ U+10FFFF
- 每个平面的码点范围可表示为U+xx0000 ~ U+xxFFFF,其中xx表示16进制的0x00到0x10,比如,平面0的码点范围为U+000000 ~ U+00FFFF,平面2的码点范围为U+020000 ~ U+02FFFF,平面15的码点范围为U+0F0000 ~ U+0FFFFF
- 再次注意:并不是每个码点就一定对应有一个字符,因为,目前Unicode字符集中有很多码点都还未被使用。
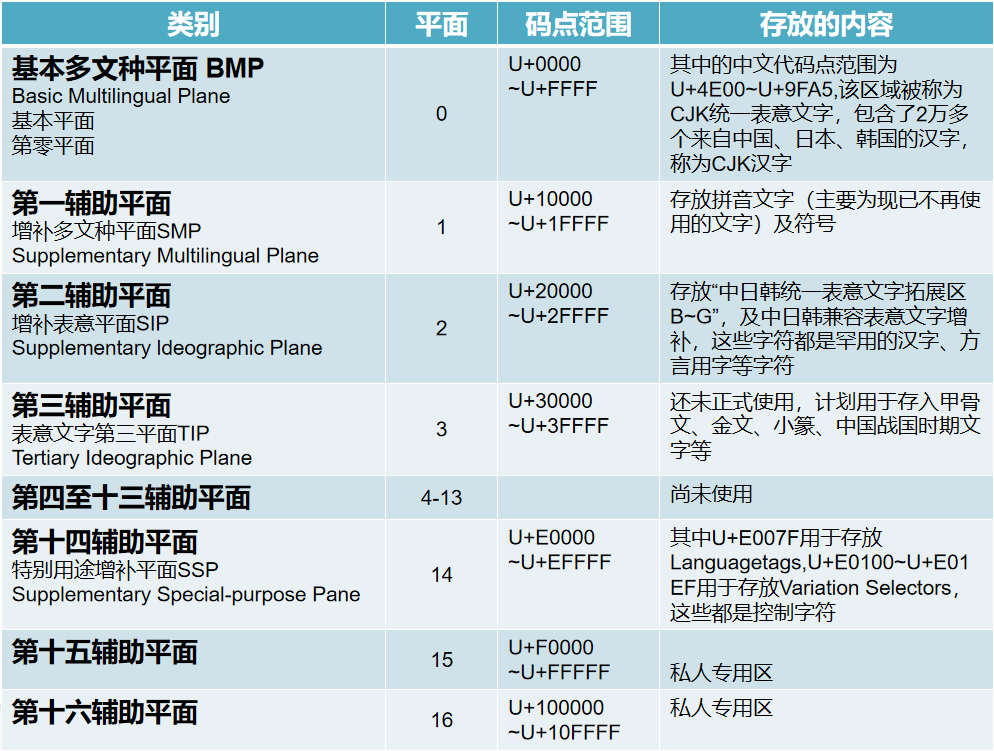
Unicode 17 层平面
2.1. UTF-16编码
UTF-16编码源于UCS-2,是Unicode最早的编码方式。
- UCS-2编码仅覆盖了基本平面(即BMP,第0平面)中的码点,使用固定的两字节将字符编号(类似于Unicode中的码点值)直接映射为字符编码,中间未经过任何的编码算法转换。
- 很明显,16位的二进制位(范围为0x0000 ~ 0xFFFF)无法表示Unicdoe引入的增补平面中的码点(平面1 ~ 16,码点范围为0x10000~0x10FFFF),为此,Unicode在UTF-16编码中使用“代理(代替)机制”来解决这个问题,代理机制使用4个字节来表示增补平面中的码点,从而使UTF-16成为一种变长编码方式。
因此,若软件仅支持UCS-2编码,则意味着仅支持UCS字符集或Unicode字符集基本平面中的字符,而不支持增补平面中的字符。
UTF-16编码后的码元序列在映射为物理意义上的字节序列时,又分为UTF-16BE (大端序),UTF-16LE (小端序)两种情况,大端序和小端序又分为带有字节序标记(with BOM)和不带字节序标记(without BOM)两种情形。比如,“ABC”这三个字符的UTF-16编码(码元序列)为:00 41 00 42 00 43;其对应的各种字节序列如下表所示:
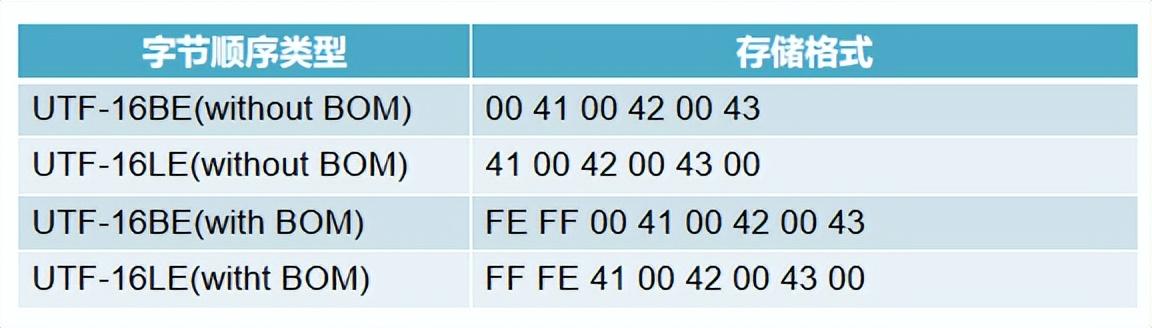
”abc”的各种UTF-16编码
2.2. UTF-32编码
UTF-32是一种将Unicode字符编码的协定,对每一个Unicode码位使用恰好32位元。其它的Unicode transformation formats则使用不定长度编码。因为UTF-32对每个字符都使用4字节,就空间而言,是非常没有效率的。特别地,非基本多文种平面的字符在大部分文件中通常很罕见,以致于它们通常被认为不存在占用空间大小的讨论,使得UTF-32通常会是其它编码的二到四倍。虽然每一个码位使用固定长定的字节看似方便,它并不如其它Unicode编码使用得广泛。
与UTF-16一样,也存在大端和小端存储。
2.3. UTF-8编码
UTF-8编码是Unicode编码的一种编码形式。由1-6个字节表示一个字符,兼容ASCII编码。
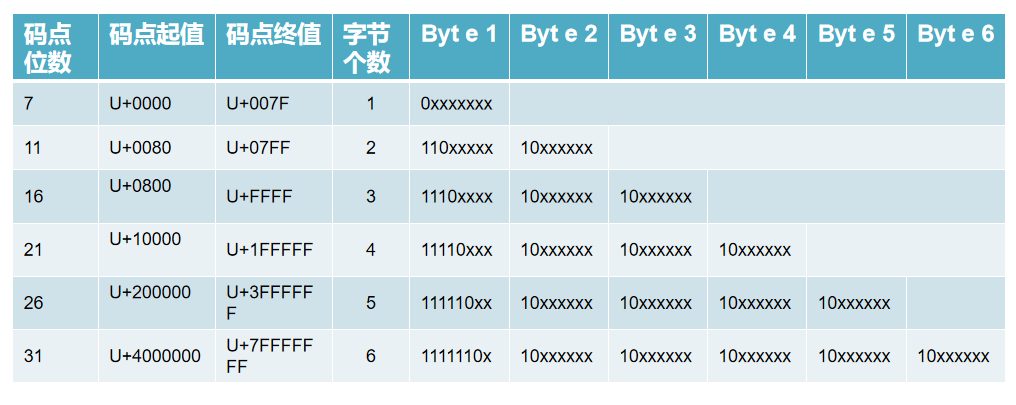
UTF-8编码
3. MFC中的字符集
MFC字符集选择多字节编码时,对应的编码是GBK编码
MFC字符集选择Unicode编码时,对应的编码是UTF-16编码。
4. QT中的字符集
QString是按UTF-16存储的。
1、当选择UTF-8编码时,QString构造函数的参数对应UTF-8编码(默认设置)。
QTextCodec *codec = QTextCodec::codecForName(“UTF-8”); QTextCodec::setCodecForLocale(codec); QString str= “右边是UFT-8编码的字符串”;
2、当选择GBK编码时,QString构造函数的参数对应GBK编码。
QTextCodec *codec = QTextCodec::codecForName(“UTF-8”); QTextCodec::setCodecForLocale(codec); QString str= “右边是GBK编码的字符串”;
3、QString也可以指定编码赋值。
QStringstr1 = QString::fromLocal8Bit(“GBK编码字符串”); QStringstr2 = QString::fromUtf8(“UTF-8编码字符串”);

QString 指定编码赋值接口
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏